文本匹配¶
在2017年之前,工业界和学术界对NLP文本处理依赖于序列模型Recurrent Neural Network (RNN).
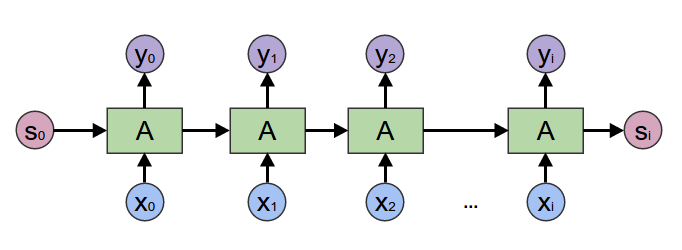
近年来随着深度学习的发展,模型参数数量飞速增长,为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集成本过高,非常困难,特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 能够习得通用的语言表示,将预训练模型Fine-tune到下游任务,能够获得出色的表现。另外,预训练模型能够避免从零开始训练模型。
本示例将展示如何使用PaddleHub Transformer模型(如 ERNIE、BERT、RoBERTa等模型)Module 以动态图方式fine-tune并完成预测任务。
文本匹配¶
使用预训练模型ERNIE完成文本匹配任务,大家可能会想到将query和title文本拼接,之后输入ERNIE中,取CLS特征(pooled_output),之后输出全连接层,进行二分类。如下图ERNIE用于句对分类任务的用法:
然而,以上用法的问题在于,ERNIE的模型参数非常庞大,导致计算量非常大,预测的速度也不够理想。从而达不到线上业务的要求。针对该问题,使用Sentence Transformer网络可以优化计算量。
Sentence Transformer采用了双塔(Siamese)的网络结构。Query和Title分别输入Transformer网络,共享网络参数,得到各自的token embedding特征。之后对token embedding进行pooling(此处教程使用mean pooling操作),之后输出分别记作u,v。之后将三个表征(u,v,|u-v|)拼接起来,进行二分类。网络结构如下图所示。
更多关于Sentence Transformer的信息可以参考论文:https://arxiv.org/abs/1908.10084
如何开始Fine-tune¶
我们以中文文本匹配数据集LCQMC为示例数据集,可以运行下面的命令,在训练集(train.tsv)上进行模型训练,并在开发集(dev.tsv)验证和测试集测试(test.tsv)。通过如下命令,即可启动训练。
使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
Step1: 选择模型¶
import paddlehub as hub
model = hub.Module(name='ernie_tiny', version='2.0.2', task='text-matching')
其中,参数:
name:模型名称,可以选择ernie,ernie_tiny,bert-base-cased,bert-base-chinese,roberta-wwm-ext,roberta-wwm-ext-large等。version:module版本号task:fine-tune任务。此处为text-matching,表示文本匹配任务。
PaddleHub还提供BERT等模型可供选择, 当前支持文本分类任务的模型对应的加载示例如下:
| 模型名 | PaddleHub Module |
|---|---|
| ERNIE, Chinese | hub.Module(name='ernie') |
| ERNIE tiny, Chinese | hub.Module(name='ernie_tiny') |
| ERNIE 2.0 Base, English | hub.Module(name='ernie_v2_eng_base') |
| ERNIE 2.0 Large, English | hub.Module(name='ernie_v2_eng_large') |
| BERT-Base, English Cased | hub.Module(name='bert-base-cased') |
| BERT-Base, English Uncased | hub.Module(name='bert-base-uncased') |
| BERT-Large, English Cased | hub.Module(name='bert-large-cased') |
| BERT-Large, English Uncased | hub.Module(name='bert-large-uncased') |
| BERT-Base, Multilingual Cased | hub.Module(nane='bert-base-multilingual-cased') |
| BERT-Base, Multilingual Uncased | hub.Module(nane='bert-base-multilingual-uncased') |
| BERT-Base, Chinese | hub.Module(name='bert-base-chinese') |
| BERT-wwm, Chinese | hub.Module(name='chinese-bert-wwm') |
| BERT-wwm-ext, Chinese | hub.Module(name='chinese-bert-wwm-ext') |
| RoBERTa-wwm-ext, Chinese | hub.Module(name='roberta-wwm-ext') |
| RoBERTa-wwm-ext-large, Chinese | hub.Module(name='roberta-wwm-ext-large') |
| RBT3, Chinese | hub.Module(name='rbt3') |
| RBTL3, Chinese | hub.Module(name='rbtl3') |
| ELECTRA-Small, English | hub.Module(name='electra-small') |
| ELECTRA-Base, English | hub.Module(name='electra-base') |
| ELECTRA-Large, English | hub.Module(name='electra-large') |
| ELECTRA-Base, Chinese | hub.Module(name='chinese-electra-base') |
| ELECTRA-Small, Chinese | hub.Module(name='chinese-electra-small') |
通过以上的一行代码,model初始化为一个适用于文本匹配任务的双塔(Siamese)结构模型,。
Step2: 下载并加载数据集¶
train_dataset = LCQMC(tokenizer=model.get_tokenizer(), max_seq_len=128, mode='train')
dev_dataset = LCQMC(tokenizer=model.get_tokenizer(), max_seq_len=128, mode='dev')
test_dataset = LCQMC(tokenizer=model.get_tokenizer(), max_seq_len=128, mode='test')
tokenizer:表示该module所需用到的tokenizer,其将对输入文本完成切词,并转化成module运行所需模型输入格式。mode:选择数据模式,可选项有train,dev,test,默认为train。max_seq_len:ERNIE/BERT模型使用的最大序列长度,若出现显存不足,请适当调低这一参数。
预训练模型ERNIE对中文数据的处理是以字为单位,tokenizer作用为将原始输入文本转化成模型model可以接受的输入数据形式。 PaddleHub 2.0中的各种预训练模型已经内置了相应的tokenizer,可以通过model.get_tokenizer方法获取。
Step3: 选择优化策略和运行配置¶
optimizer = paddle.optimizer.AdamW(learning_rate=5e-5, parameters=model.parameters())
trainer = hub.Trainer(model, optimizer, checkpoint_dir='./', use_gpu=True)
优化策略¶
Paddle2.0提供了多种优化器选择,如SGD, AdamW, Adamax等,详细参见策略。
其中AdamW:
learning_rate: 全局学习率。默认为1e-3;parameters: 待优化模型参数。
其余可配置参数请参考AdamW。
运行配置¶
Trainer 主要控制Fine-tune的训练,包含以下可控制的参数:
model: 被优化模型;optimizer: 优化器选择;use_vdl: 是否使用vdl可视化训练过程;checkpoint_dir: 保存模型参数的地址;compare_metrics: 保存最优模型的衡量指标;
Step4: 执行训练和模型评估¶
trainer.train(
train_dataset,
epochs=10,
batch_size=32,
eval_dataset=dev_dataset,
save_interval=2,
)
trainer.evaluate(test_dataset, batch_size=32)
trainer.train执行模型的训练,其参数可以控制具体的训练过程,主要的参数包含:
train_dataset: 训练时所用的数据集;epochs: 训练轮数;batch_size: 训练时每一步用到的样本数目,如果使用GPU,请根据实际情况调整batch_size;num_workers: works的数量,默认为0;eval_dataset: 验证集;log_interval: 打印日志的间隔, 单位为执行批训练的次数。save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
trainer.evaluate执行模型的评估,主要的参数包含:
eval_dataset: 模型评估时所用的数据集;batch_size: 模型评估时每一步用到的样本数目,如果使用GPU,请根据实际情况调整batch_size
模型预测¶
当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在${CHECKPOINT_DIR}/best_model目录下,其中${CHECKPOINT_DIR}目录为Fine-tune时所选择的保存checkpoint的目录。
以下代码将使用最优模型来进行预测:
import paddlehub as hub
data = [
['这个表情叫什么', '这个猫的表情叫什么'],
['什么是智能手环', '智能手环有什么用'],
['介绍几本好看的都市异能小说,要完结的!', '求一本好看点的都市异能小说,要完结的'],
['一只蜜蜂落在日历上(打一成语)', '一只蜜蜂停在日历上(猜一成语)'],
['一盒香烟不拆开能存放多久?', '一条没拆封的香烟能存放多久。'],
]
label_map = {0: 'similar', 1: 'dissimilar'}
model = hub.Module(
name='ernie_tiny',
version='2.0.2',
task='text-matching',
load_checkpoint='./checkpoint/best_model/model.pdparams',
label_map=label_map)
results = model.predict(data, max_seq_len=128, batch_size=1, use_gpu=True)
for idx, texts in enumerate(data):
print('TextA: {}\tTextB: {}\t Label: {}'.format(texts[0], texts[1], results[idx]))
依赖¶
paddlepaddle >= 2.0.0
paddlehub >= 2.0.0